content type paperpublished May 2025
SPD: Sync-Point Drop for Efficient Tensor Parallelism of Large Language Models
AuthorsHan-Byul Kim, Duc Hoang, Arnav Kundu, Mohammad Samragh, Minsik Cho
AuthorsHan-Byul Kim, Duc Hoang, Arnav Kundu, Mohammad Samragh, Minsik Cho
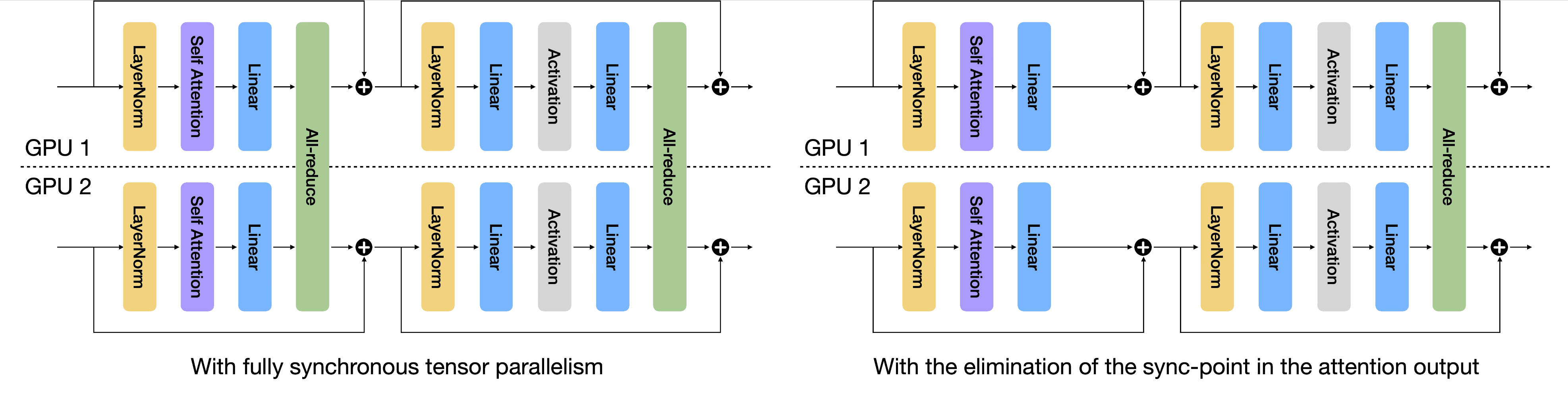
With the rapid expansion in the scale of large language models (LLMs), enabling efficient distributed inference across multiple computing units has become increasingly critical. However, communication overheads from popular distributed inference techniques such as Tensor Parallelism pose a significant challenge to achieve scalability and low latency. Therefore, we introduce a novel optimization technique, Sync-Point Drop (SPD), to reduce communication overheads in tensor parallelism by selectively dropping synchronization on attention outputs. In detail, we first propose a block design that allows execution to proceed without communication through SPD. Second, we apply different SPD strategies to attention blocks based on their sensitivity to the model accuracy. The proposed methods effectively alleviate communication bottlenecks while minimizing accuracy degradation during LLM inference, offering a scalable solution for diverse distributed environments: SPD offered about 20% overall inference latency reduction with <1% accuracy regression for LLaMA2-70B inference over 8 GPUs.
November 19, 2024research area Methods and Algorithms, research area Speech and Natural Language ProcessingWorkshop at NeurIPS
July 17, 2024research area Methods and Algorithms, research area Privacyconference USENIX Security

Our research in machine learning breaks new ground every day.